构建外脑 / 智变时代的个人知识管理

作为一名 AI 乐观派,Linkedin 的创始人 Reid Hoffman 在他今年初与 ChatGPT 协同撰写的新书《Impromptu》(我和 GPT-4 协同翻译了中文版《GPT 时代人类再腾飞》)中最重要的一个结论就是:不应该把 AI 看作威胁,而应该当作伙伴,一个可以帮助我们充分发挥作为人类的潜力的伙伴。2022 年底推出的 ChatGPT 让我们看到了 AI 的潜能,大语言模型涌现出来的理解、表达与推理能力,会让人类与机器的协作效率,在计算机、互联网之后,上升到一个新的台阶。
本文将探讨在新一轮的 AI 变革之下,如何用新工具来帮助扩展大脑思维与记忆的边界,以及知识工作流的新方法,激发潜能,构建外脑!全文 12000 字左右,预计阅读时间 30 分钟左右。
1. 大脑之外
乔布斯早在 1980 年就把个人电脑比作“大脑的自行车”,那是我们在电力革命之后,首次拥有了能够扩展大脑计算能力的工具;随后的互联网,让我们可以瞬时直面全球信息,通过搜索引擎快速找到需要的任何资讯,大脑的记忆能力也被扩展了,但这一切都在“大脑之外”。
那些对我们来说有价值的信息,只是静静躺在网络节点记忆体中的比特,即使能检索到它们,那也并不是我们大脑神经元中的连接,或者说是你的“知识”。我们每天都花费很多时间看社交网络、看新闻、听播客还有阅读电子书籍,让自己感觉在不断学习以获得“知识”和提升自我。然而,这些宝贵的“知识”当我们需要它时,真可以像条件反射那样调取么?
我们的大脑无法记住所有我们看过的细节,因为在任何时候,它们都只能存储一些想法。虽然科学家依旧没有研究出来大脑产生记忆的核心机制,但记忆肯定不是像比特那样写入记忆体的,在数亿万记的神经元连接中,大脑产生了意识,让我们有了记忆的感觉,无数的想法在这个生物的神经网络里时刻涌现着,直到我们用合适的神经通路让这些想法连接,最后再通过那个主观的自我“意识”解释出来。
所以从根本上说,我们的大脑是用来创造想法的,而不是用做储存的。
1.1 扩展记忆与智力
想要真正在“大脑之外”来强化大脑,就需要建立一种机制或者系统,可以持久的保存通过经验获得的想法,加快把信息转换成知识的速度,帮助激发灵感和创建想法之间的连接。
过去二十多年互联网的普及和移动设备的进化,知识工作者手边有了易用的数字笔记本、强大的文档存储与思维整理工具,它们为创建“外脑”提供了一条清晰可行的路径 —— 用一个外部的数字化的集中方式,来存储我们关心的信息和记录所学到的东西。我们有了属于自己的可以随时访问的数字扩展记忆。
现在,以 GPT-4 为代表的大语言模型(LLM)让我们在搜索引擎之后,有了一个全新的智能引擎,这让数字化的扩展智力成为了可能。语言模型用人类的全部语料来训练,最新的集成了视觉模态(LMM)的 GPT-4V 还能很好的理解图像,它们封装了人类的所有的知识,随着数字神经网络规模的扩大,涌现出来了对常识的认知,还能灵活的使用自然语言表述和推理。有了 LLM 我们就可以在大脑和外脑之间搭建一个利用自然语言通讯的接口,在记忆之外,完成了智力扩展的拼图。
OpenAI 的首席科学家伊尔亚·苏茨克维(Ilya Sutskever)有一个信念:“如果你能够高效地压缩信息,你就已经得到了知识,不然你没法压缩信息”。所以你想高效压缩信息,你就一定得有一些知识,所以他坚信 GPT-3 以及最新的 GPT-4 已经有了一个世界模型在里面,虽然它们做的事情是预测下一个单词,但它已经表达了世界的信息,而且它能够持续地提高能力!
1.2 ExoBrain 的概念
为了更好的表述这种在大脑之外,利用软件工具还有大语言模型相关的技术,来扩展我们记忆和智力的新机制或者系统,我将其称之为 ExoBrain - 外脑。后文都用中文外脑来表述 ExoBrain。
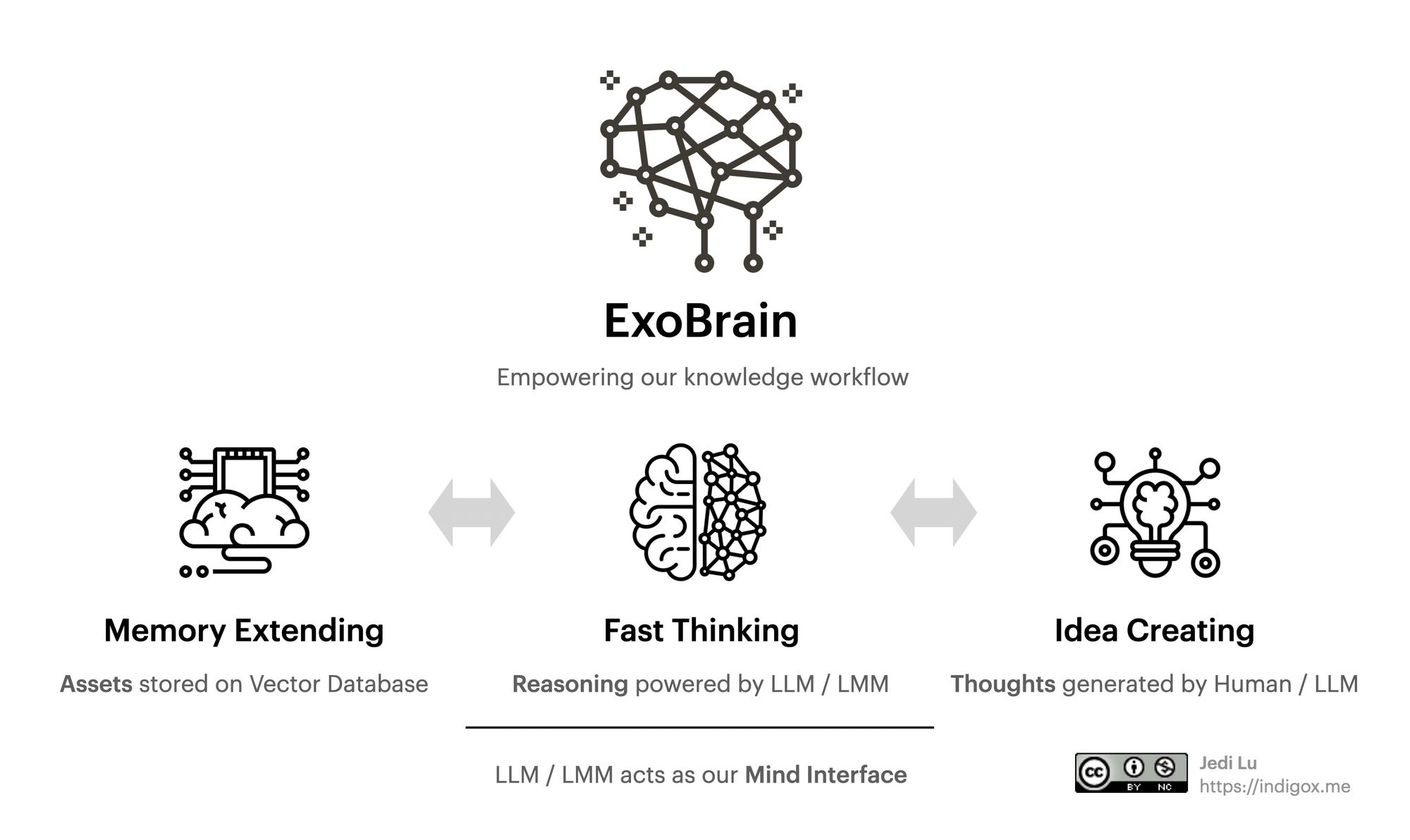
语言模型是心智界面
对话是最简洁的人机界面,ChatGPT 的流行让真正的人机对话成为了可能,现在 Google 的 Bard,Anthropic 的 Claude 还有 inflection 的 Pi.ai 都卷入了这场智能入口之争。这些语言模型除了可以用它们储备的全人类的知识库来响应我们的任何问题之外,还能够快速理解复杂的文档,生成想法甚至驱动其它的软件来自动化的完成任务,语言模型就是我们的心灵副驾(Mind Copilot),自然语言输入,自然语言输出。
语言代表了人类的智能,当我们思考的时候实际上是在进行内心独白和基于语言的逻辑推理。同样,我们用和 LLM 之间的对话来实现快速理解,记忆唤起、想法连接和驱动外部软件自动完成工作,LLM 就像一个智能引擎一样成为了我们和外脑之间的 心智界面。
容易唤醒的数字记忆
随着大语言模型的流行,笔记工具还有文档存储服务也都在智能化,例如 Notion AI 还有 OpenAI 投资的 Mem.ai,一款 AI 驱动的笔记工具。数字记忆的核心就是在我们需要的时候,可以快速唤醒,在几年前还是非常冷门的矢量数据库(Vector Database)也跟着 LLM 的流行而爆发,我们可以用自然语言的方式快速检索,然后把内容交给 LLM 处理后用自然语言回应,唤醒自己的数字记录就像和自己的心灵对话一样顺畅。
Google 正在将 Bard 整合到 Workspace 产品线中,很快就能体验到和 Google Drive 对话的感觉,存储在 Google 的任何文档都是我们的数字记忆,Bard 作为 Google 这个外脑系统的心灵界面,将代理我们与自己在 Google 的数字资产交流。
生成式的想法连接创意
在旧的系统设计中,我们不会让软件机械化的生成创意,但像大语言模型这样的生成式 AI 它们的本质工作就是生成内容,配合图像生成模型,还能实现文本到图像、文本到视频的视觉化创意。在一个外脑的系统中,就是利用存储的想法生成新的想法,这个过程不仅能够使用语言模型的全局知识,还可以用到我们自己存储的专属知识。或许生成的想法和创意很离谱,但我们的大脑也是这样,在一个接一个的想法涌现下寻找灵感的。
下一小节,我们来了解大脑如何创造想法。这个至关重要,大脑的工作机理将会决定我们如何设计最合适的外脑工作流。
2. 创造力的激发
知名畅销书作家史蒂芬·科特勒(Steven Kotler) 在 2021 年出版的《The Art of Impossible》一书(中文版《不可能的技艺:巅峰表现入门》)中,用大量最新的脑科学知识探讨了激发学习潜能、创造力和心流的方法,其中关于如何训练创造力的生理解释,对于我们构建 ExoBrain 的工作流非常受用!
什么是创造力?创造就是想法的连接,把两个看似不相干的事物,组合在一起就成了有趣的新东西。这里面没有算法,也没有固定的流程,创造力往往是灵光乍现,让人感到很神秘。其实心理学家、诺贝尔经济学奖获得者丹尼尔·卡尼曼(Daniel Kahneman)在《 Thinking, Fast and Slow》(中文版《思考,快与慢》)一书中就提到了大脑思考的两个系统,分别是:
- 系统 1 的运行是无意识且快速的,不怎么费脑力,没有感觉,完全处于自主控制状态;
- 系统 2 将注意力转移到需要费脑力的大脑活动上来,例如复杂的运算。系统 2 的运行通常与行为、选择和专注等主观体验相关联;
在科特勒的理论中,设想大脑中有三套神经网络系统,每个系统都涉及到若干个脑区,虽然它们彼此重叠,但这三个网络有完全不同的思维功能,万维钢老师在精英日课第四季《不可能的技艺》里做过总结,在这里引用一下:
第一个网络叫「注意网络」Central Executive Network,它的作用是决定你的注意力在哪,你当前着重思考的是什么。它的工作方式就好像是一个聚光灯,注意力网络能锁定思考的对象,让你专注于一件事。
第二个网络叫「想象网络」Default Mode Network),它负责做白日梦。其实大脑这时候是高度活跃的,能耗并没有降低,你是在漫无边际地想各种各样的事儿:也许是回忆,也许是编故事,也许是在猜测别人的想法。你没有任何刻意的控制,各种想法随机地往外冒。
所以「想象网络」是创造力的关键,它可以让你脑子里遥远的概念和想法得到链接。「注意网络」是着重想一件事,是集中思维,「想象网络」是随时往外冒想法,是发散思维,两者快速切换,配合得当创造力就出来了。那这个切换是怎么发生的呢?你还需要第三个网络。
第三个网络叫「突显网络」Salience Network,它的作用是时刻监视各种想法和各种信息,评估它们的重要性。「想象网络」蹦出一个想法,如果突显网络认为它是重要的,就会开启「注意网络」去考虑这个想法;反之就自动忽略,让「想象网络」继续漫步。优秀的「突显网络」能帮你注意到一般人注意不到的东西,别人眼中可能没什么有意义的信息,而创造力强的人却能从中发现灵感和启发。
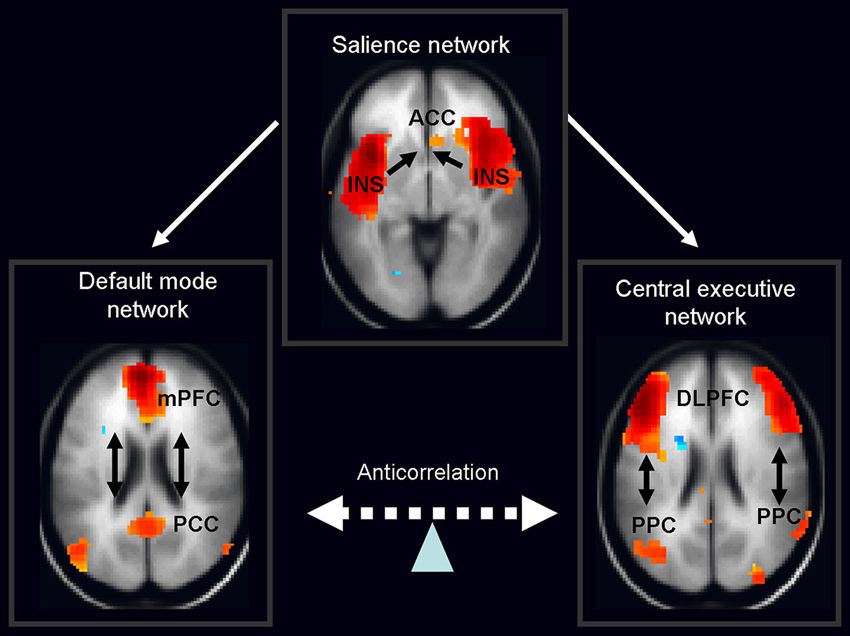
所谓训练创造力,就是让这三个网络火力全开,能够快速自然地切换!而要想让三个网络都活跃起来,你需要一个关键的东西,这就是大脑中的“前扣带皮层”(Anterior Cingulate Cortex - ACC)。ACC 同时存在于注意力网络和突显网络之中。有多项研究表明,在灵感迸发的那个 WOW 时刻之前,大脑的 ACC 都是活跃的,是处在点亮的状态✨
现在,我们的手边已经有了外脑(ExoBrain)的概念模型还有大脑激发创意的系统方式,接下来我们一起来寻找一套可以适应这个思维框架的具体方法,激活外脑!
3. CODE 方法论
如果我们在 Google 上搜索第二大脑(Second Brain),会发现被提及最多的一本书,就是来自 Tiago Forte 在 2022 年出版的《Building a Second Brain》。Tiago 提出了一种经过验证的方法 - CODE,可以有效的组织我们的数字生活并释放创造潜力。
相信几乎所有的知识工作者,都在面临过信息过载的时候发现脑子不够用,我们感觉看过很多东西,却什么有价值的知识都没摄取到;我们想过用各种方式来组织自己学到的知识,却发现需要使用的时候依然找不到。。
因此,需要有可行的方法能够帮我们做到:
- 管理个人信息流来减轻“信息过载”的压力;
- 保存能接触到的全部学习资源,文章、播客、书籍等等,我们无需记住所有细节;
- 能够快速找到看过、学过和思考过的任何内容;
- 以结果为导向的方式组织和读取我们存储的外部知识;
- 花更少的时间搜寻,用更多的时间来做想法连接,也就是 创意工作;
- 随着我们对这个外部的知识库的积累,我们能形成自己的洞见,也就是对 知识的内化;
CODE 方法的目标就是用外部工具与方法论来强化大脑的创造力,弥补我们生物大脑的先天不足。这个简单的方法由 捕获(Capture), 组织(Organize), 提炼(Distill)和 表达( Express)四个步骤组成,CODE 就是这四个步骤首字母的缩写。

Tiago 在他的网站上有一篇名为《Building a Second Brain: The Definitive Introductory Guide》的博客,详细的介绍了 CODE 方法论,不过我个人认为 组织(Organize)的架构要优先与捕获(Capture),这是整个系统运作的框架,相信很多同学都溃败在 建立完美分类的乌托邦 之下,我把最有价值的这部份给大家分享一下。
PARA 信息组织法
大多数人倾向于按主题组织信息,类似于图书馆中使用的类目系统,或者像书店的书籍分类。对于数字笔记,最好使用更简单、灵活的组织方法。组织信息的最佳方法是专注于正在进行的项目。当我们遇到新的信息时,想想它会如何帮助推进目前正在做的事情。
Tiago 经过十多年的个人实验,教授数千名学生后,开发了一种组织信息的方法 - PARA,一个简单,全面又其灵活的系统,可以用于组织任何平台上的任何类型的数字信息。PARA 方法基于一个基本的原则:我们生活中的所有信息只分为四类。
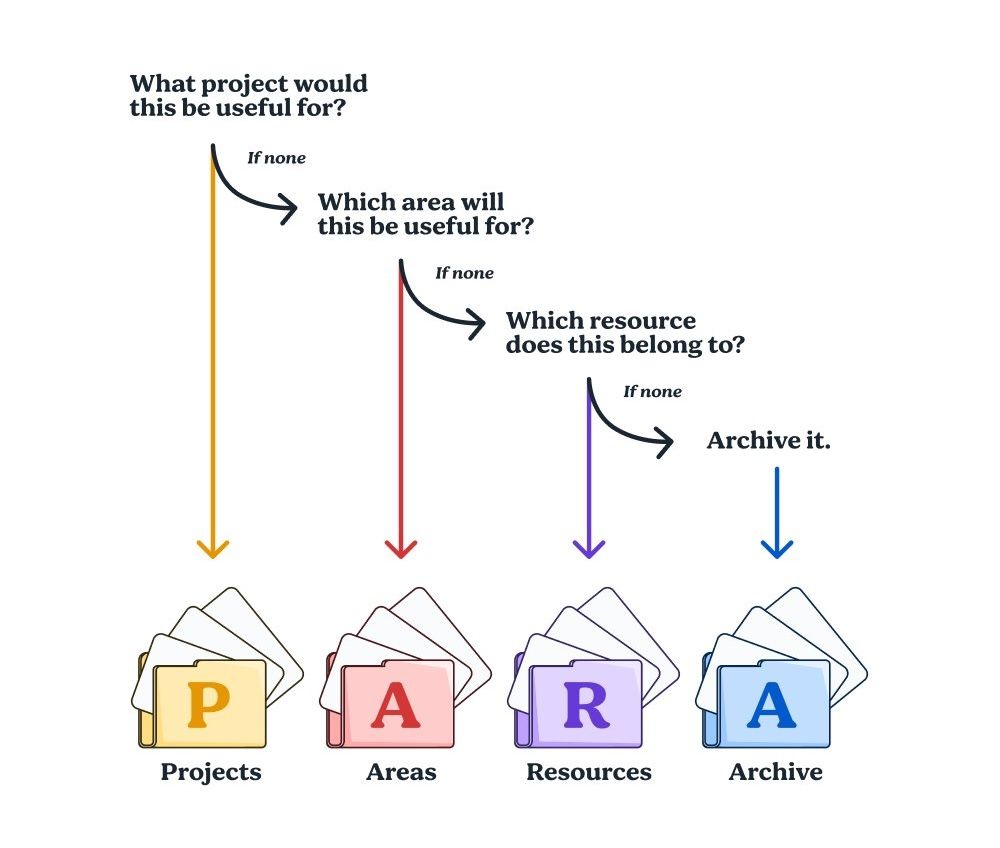
- 项目(Projects):短期正在进行的项目(工作或个人生活中的项目)
- 领域(Areas):希望长期关注的领域(个人的长期兴趣)
- 资源(Resources):将来可能用到的主题资源(例如图片、视频、模版等等)
- 存档(Archive):其他三个类别中的非活动项目(我们需要定期归档收藏的资源)
我自己已经在所有的数字系统中使用这个分类法,包括桌面上的工作文件夹、收藏夹、笔记的分类,还有 Google Drive 以及电邮的分类方式。存档(Archive)分类是个十分神奇的存在,它就像“时间胶囊”,可以保留一切,我们只需用时间线索来回溯存档。因为搜索功能的增强,存档实际上是让机器来查阅的资料库,利用检索或者 智能问答 来从这个资料库快速获取内容是最方便的做法,最好的分类就是无需分类。
捕获与提炼
避免“信息过载”的原则之一就是只保留能引起共鸣的东西。我在 激发创造力 那一小节中介绍了大脑中“突显网络”的工作机制,这就是一个生物筛选器,什么重要应该关注,什么不用理会。当然发现机会是个非常重要的个人能力,这个和经验、性格很多因素有关。但 PARA 方法之下,有一个清晰的信息筛选流程(参见图 04):
- 这对哪个项目有用?
- 如果没有:这将对哪个领域有用?
- 如果没有:这属于哪个资源?
- 如果没有,最好存档此信息或根本不保存。。
练习几次就能轻松掌握,但不要过度思考如何在 PARA 中归类。 使用简单的搜索,几乎可以肯定再次找到任何内容。
Every.to 的创始人 Dan Shipper 写过一篇《The End of Organizing》,里面提到一个观点:做笔记就是与未来的自己建立联系。笔记是 CODE 方法论中 提炼(Distill)环节的核心,把笔记想象成时间旅行,你正在向未来的自己发送 知识包(Knowledge Packages)。
在捕获到的信息中,把那些需要重点阅读、思考的内容进行标记,通过笔记的方式摘要出来,写上自己的思考,无需完美也不用讲究格式,一次一点,就像蒸馏提纯一样,做到每一次记录都增加这份笔记的价值。在这个过程中,需要形成自己的一些记录风格,例如关键词、内容提示以及在文章中高亮显示的颜色卡片规则等等,给当时不理解的内容加上参考来源,笔记中引用的外部信息一定要添加指向的网站、文件或电子邮件的链接。
利用 CODE,我们的外脑(ExoBrain)就有了被验证过的方法论。从搭建组织信息的架构开始,捕获有价值的内容,深度理解,提炼笔记,让它们成为连接想法的节点,一个独特的只属于自己的知识网络就会慢慢成型。这里还有最后一个步骤 表达(Express),如果我们不断地强迫自己输入越来越多的信息,但从未真正使用它们,那这些“大脑之外”的信息是没法生长成我们生物脑中的神经元连接的。学习过程中知识的内化十分重要,无论是 Tiago 的 CODE 方法论还是大名鼎鼎的费曼技巧,都有对外输出的环节。我将下一小节中结合我的工作流来分享自己的心法,也会详细介绍表达的方法。
4. 外脑心法
在今年一月,写过一篇关于自己学习方法的长文《费曼学习法实践 / INDIGO 的信息获取与知识输出方法论》,详细讲解了费曼学习法,以及如何在这个方法的指导下记录笔记、对外输出和内化知识。现在,大半年的时间过去了,OpenAI 的 GPT-3.5 已经从 LLM 进化到了多模态(LMM)的 GPT-4V,Midjourney 也能生成照片级别的图片,我自己对把 信息压缩成知识 这个过程也有了新的认知。为了更加聚焦在这个事情上,还拉朋友一起成立了 Hallid.ai Lab 来研究如何利用大语言模型来增强大脑的效率,也就是第一小节中提到的外脑(ExoBrain)的概念。
之前的经验是把信息获取分成了「随机漫步」和「聚焦阅读」两种方式,在了解了大脑的注意网络和想象网络机制后,结合 CODE 方法论中的组织、提炼与表达步骤,我重新设计了自己的 外脑心法 工作流,如下图所示:
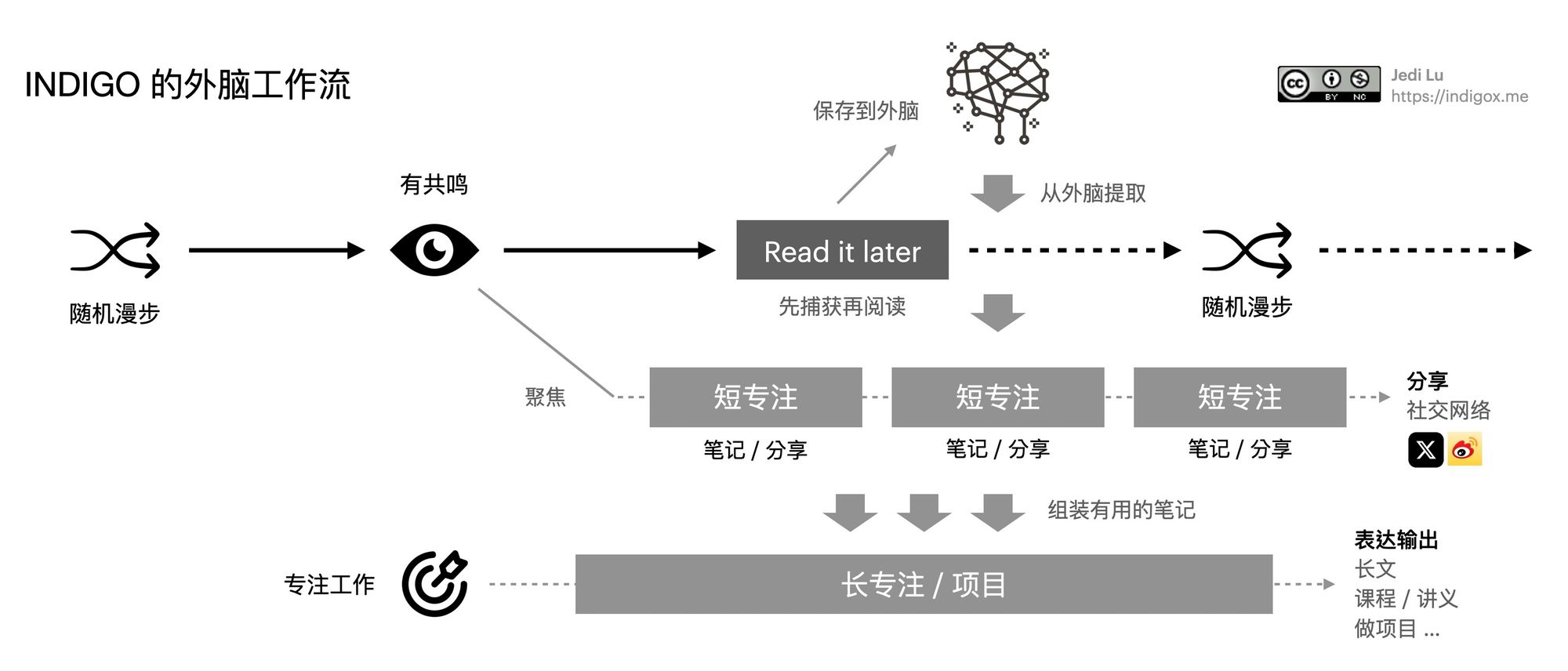
让外脑来帮助减轻记忆的负担,我们可以释放自己生物大脑的天性,去想象、创造和全神贯注。
长短专注
借用大脑的工作逻辑,要在外脑中也启用「专注网络」,那些来自外部的杂乱的信息洪流就像我们大脑中时刻涌现的想法,决定把什么信息直接忽略,把什么信息放入归档,决定立刻专注什么,我们外脑的「突显网络」要在 PARA 分类法下开启工作。
为什么要把专注区分成「长」与「短」呢?
很多情况下,我们有许多需要耗费长时间才能完成的工作,例如执行一个项目、学习一个技能或者是写一本书或者长文,我们没法在短时间内集中精力「快炒」,这需要「慢炖」。长专注应该是 PARA 分类中优先级最高的项目(Project),捕获信息的时候,需要优先考虑它。
慢炖的好处是你可以同时专注多个项目,还可以「短专注」其它的东西,当我们在阅读, 观看和聆听的时候,如果有关注领域(Area)或者热点(Trending)信息出现时,就可以切换注意力,在短时间内「快炒」一个信息,从捕获(存储到外脑),到提炼(理解并完成笔记),再到表达(重新组织语言分享给别人)。这些「短专注」的成果将会成为完成「长专注」项目的材料,所以随着时间的推移,我们并没有一次做完一个大项目,而是在以「短专注」的工作方式积累大项目的各自素材、思考与灵感。
短专注会让处理碎片化的信息的耗时更有意义!通常,我会用社交网络(X & Weibo)来分享一个「短专注」的成果,但更多「短专注」提炼的笔记会保存在 Notion 里面,供后续学习和写作使用。长专注对于我来说是一个必须完成的项目,可以是写一篇长文、做一个培训课程或者是启动一个真实的项目来开发产品。完成一个长期专注的交付,会让自己身心愉悦,有巨大的收获感,外脑的知识和自己大脑在此时终于完成了连接 🔗
借用创造力
毕加索(Pablo Picasso)有句名言:优秀的艺术家复制,但伟大的艺术家剽窃!
很多人都直觉地认为:所谓创造力,就是一种原创的能力。但事实并非总是如此,创造力就是重新混合。根据我们读到、看到和听到的东西,来获取那些已经存在的想法,然后添加自己的观点,并以有趣的方式重组,从而产生出增量的价值,这就是创造力。
在外脑(ExoBrain)的设计概念中,我特意安排了三个模块,分别是存储(Memery)、理解(Reasoning)和创造(Creating)。如果从我们阅读的所有东西,挑选出能产生共鸣的小片段,再把所有这些放在一个地方,那么我们就能看到之前很多不容易观察到的连接,或许新的有趣的想法就从这些连接中诞生了。但如果我们试图在脑海中做这一切,对比用工具干这些,效果会差很多。或许,我们可以把这种机制称为来自外脑的创造力。
因为我自己平时主要的输出都是文字,现在用 ChatGPT 或者 Claude 来做这种笔记内容的提炼和再创作会非常很合适,还有 Notion AI 也是很常用的工具,特别是在我拟定一个简单主题的时候,让它帮忙自动延展或者解释一下,有助于产生新的想法连接。相信在视觉创作领域,已经有不少同学都是拿 Midjourney、DALL·E 3 还有 Stable Diffusion 的开源工具来混合创意了。
灵感捕获法
在第一小节“大脑之外”中就提到了:我们的大脑是用来创造想法的,而不是用做储存的。因此,每当我们的大脑因为一些事情的共鸣,涌现出想法的时候,无论是在阅读、看视频、听播客,还是在走路甚至是在洗澡的时候,我们都想尽快捕捉到这个想法,因为我们的大脑的这个记忆状态不会保持很长时间。其实,我自己大多数绝妙的想法都是在淋浴时想到的,但等洗完大多数都给忘记了。
捕获共鸣信息的工具
- 想法冒出的时候,手边没有任何可用于记录的设备,那就让大脑专注在这个想法上,保留尽可能多的线索等待回忆时整理出来;
- 看到的任何文字、图片以及自己涌现的灵感,有手机在身边,就用 Apple Note 随手记,这是我个人快速记录的必备工具;
- 阅读到想保存下来的任何文章、视频、播客以及图片,都用 Mymind,当然这是个人偏好,其实 Read it Later 的工具还有 Readwise、Pocket 以及 Instapaper,对于网站收藏我会单独使用 Raindrop 为了跨平台和检索方便;
- 最后那些大块头的 PDF、DOCX 文件,全部保存在 Google Drive 里面,这样可以跨终端而且检索十分方便,Google 最终肯定会让自己的 AI 来分析你保存在它那儿的全部信息的,而且 Bard 正在这样做了。。
让未来的自己更轻松
用笔记的方式提炼捕获的信息,这些都是发送给未来自己的知识包。我会把专注过程的笔记,全部用 Notion 保存,因为结构高度定制化,怎么折腾都行。但缺点也很明显,什么都得手动来,虽然有很多摘要工具能够自动同步 Notion,但专注的过程就是要亲自整理笔记才有意义。
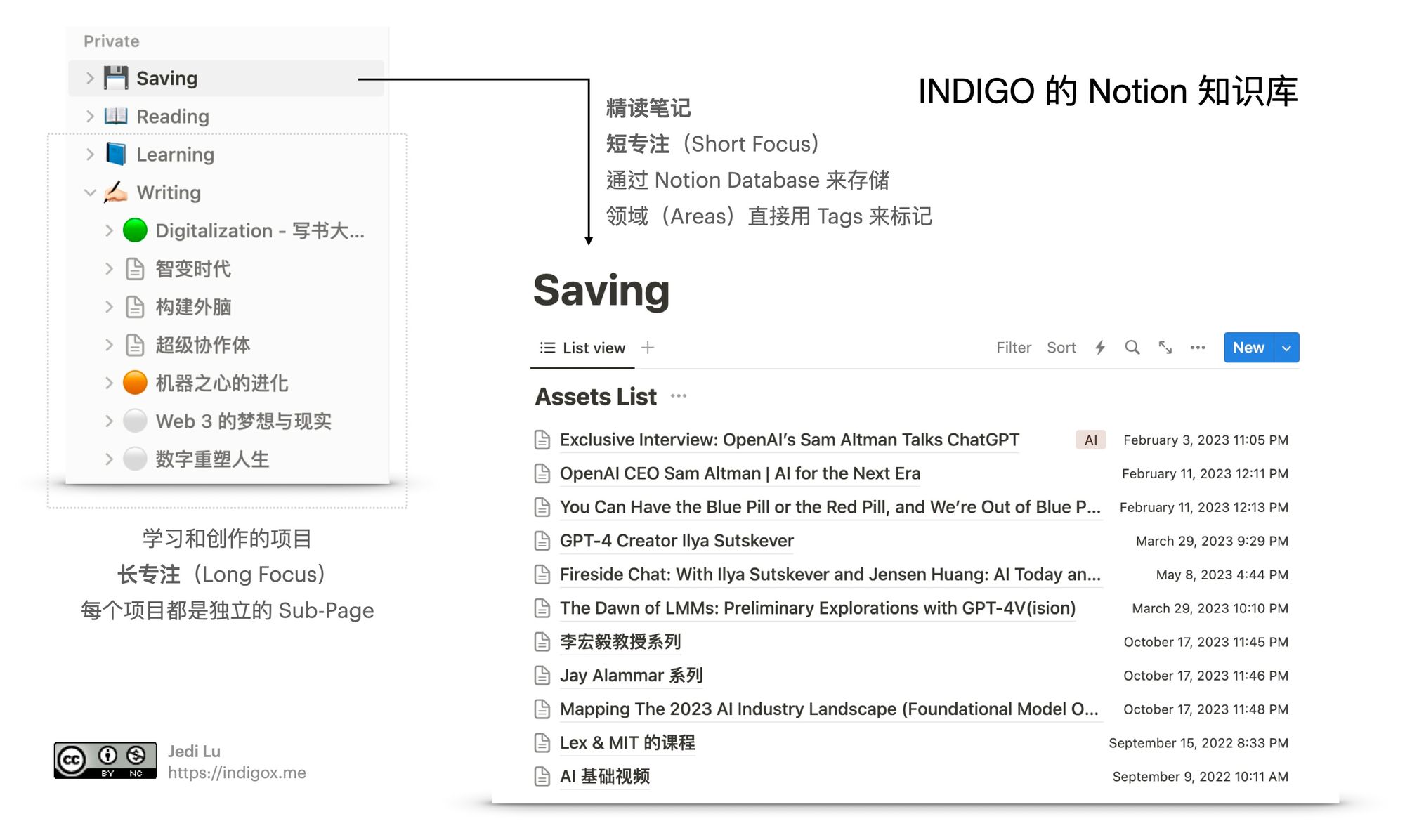
参照 PARA 的分类方式,全部需要专注学习的内容,都会按照收录的内容创建 PAGE,每个 PAGE 就是一个对应专项的笔记;具体属于哪个领域(Area)用 PAGE 的 TAG 来分类就好了。这个方式适合「短专注」,如果是「长专注」则会创建一个项目(Project)PAGE,这里就能用前面提到的“借用创造力”的方法,记录很多想法连接的笔记,供后续项目的表达用。
简单来说就是用多种工具捕获灵感,然后在统一的地方提炼笔记,形成一个自己理解的可供未来使用的中间知识包,让未来的自己更轻松!
输出即学习
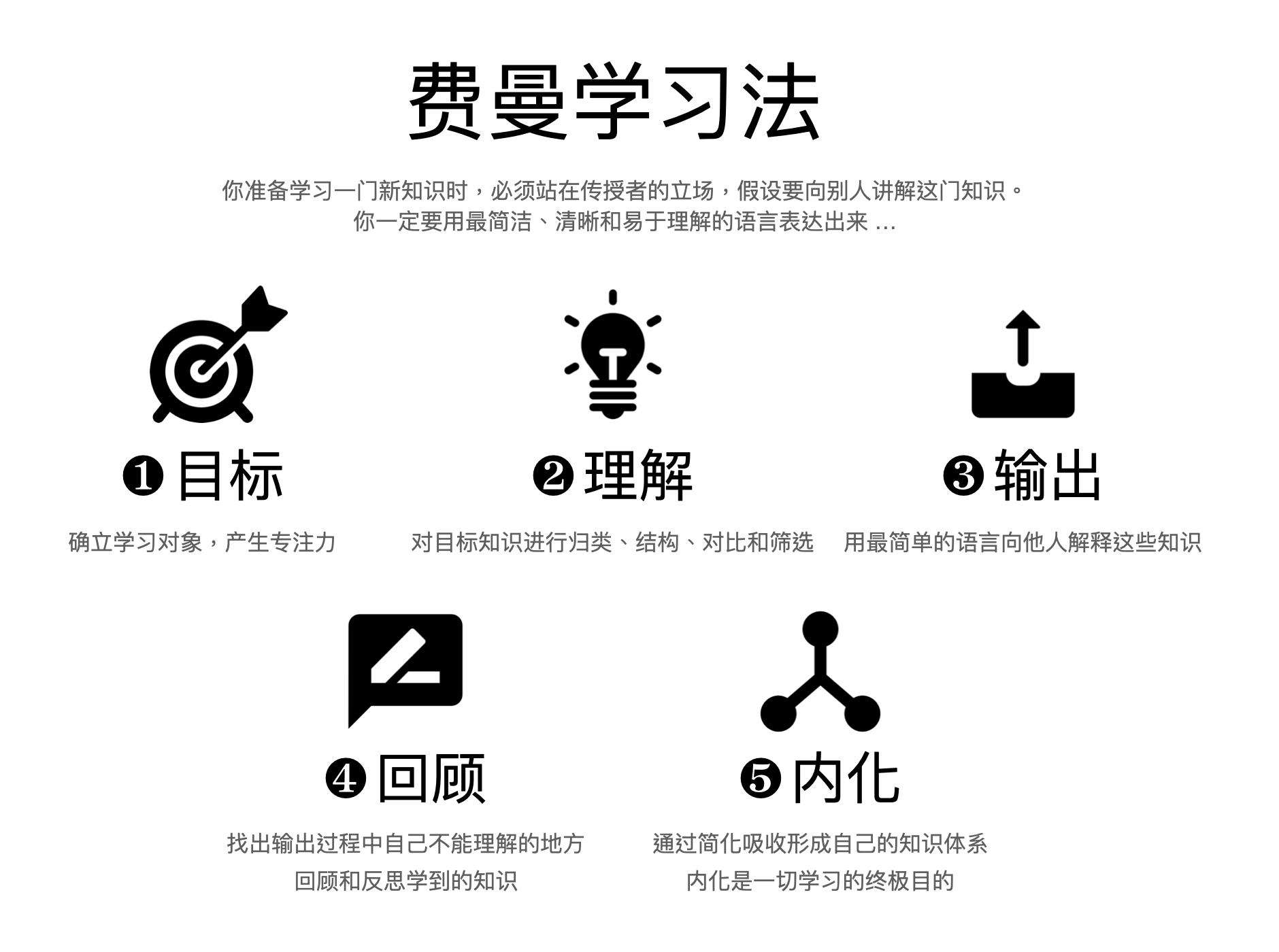
这里需要再次提到费曼学习法,也叫费曼技巧(Feynman Technique)。我自己的针对某些领域的深度学习,创作长篇内容以及制作培训课程的过程中反复使用过,非常有效。CODE 方法论的最后一步就是表达(Express),把在外脑中记录的信息,通过创作提炼后,内化成我们生物大脑可以熟练运用的知识,从而可以非常自然的对外表达分享出来。我们可以把费曼技巧用在「长专注」的项目上,具体步骤如下:
- 目标:确立学习对象,产生专注力;
- 理解:对目标知识进行归类、结构、对比和筛选;
- 输出:用最简单的语言向他人解释这些知识。费曼特别提到了讲解对象是六年级的小学生,这是一个泛指,主要是他的词汇量和认知足以理解基本概念以及之间的关系;
- 回顾:找出输出过程中自己不能理解的地方,回顾和反思学到的知识;
- 内化:通过简化吸收形成自己的知识体系,内化是一切学习的终极目的;
输出可以是创作任何东西,但当我们写一篇文章、论文、演讲或是任何能给别人分享讲解的东西时,都会遇到一个问题,我们倾向于从一张白纸开始。这时我们搭建的 外脑系统 就能发挥作用了,随着时间的推移我们收集了所有这些领域的相关信息,还有想法灵感的点点滴滴,我们永远不会真正从头开始,在我们准备创作输出之前,手边已经有了足够多的资料,那些文章、摘录,还有日积月累的笔记。现在,通过检索就能轻松访问这些资料,如果配合 LLM 的生成能力,我们只需要通过提问就能完成很多内容创作。
拿我自己的习惯来举例,在确定写长文输出之前,先把这个主题的信息结构整理清晰,做一个叙事框架,通常会在正式开写一个月以前就确定好框架。如果是自己不太熟悉或者非常新兴的领域,就得先看完几本这个领域的书或者是连载的博客。现在这篇长文输出就是一个「长关注」项目,而且我也在文章中混合了很多之前收集的笔记还有以前创作内容的片段,但这篇确实是新思考的输出。
就像前面提到的,Notion 是创作过程中最主要的信息整理工具,我会为要写的主题专门建立一个 PAGE,用来做关联链接收藏、深度阅读摘录和写创作草稿,这时也可以在不同的概念之间强行建立联系,让创作的内容更有广度和跳跃性。最终正式的文章通过 Google Docs 汇总成文输出!
我们可以在外脑中储存无限多的信息,也可以整理无数的笔记,但组成外脑的工具最终都是要让自己真正学会而存在的,因此所有的输入都是为了在合适的时候做一个漂亮的表达,输出即学习。
在系统化的构建外脑后,你将开始变得与众不同。你不再孤立地思考事物,而是融入思想网络的整体,在这个网络中,一切都会相互影响,想法的连接在一个数字化的网络中被激活。你会意识到,在飞机杂志上读到的随机内容,会对你正在写的博文有帮助,你在工作中学到的关于有效沟通的方法也适用于你的家庭辩论。。现在有搭建理想中的外脑(ExoBrain)的完美工具集么?如果还不存在,那新的工具应该有哪些特性?我会在下一节中展开讨论。
5. 理想的工具
虽然说构建外脑(ExoBrain)的核心是思维方式与执行方法,一种有效组织消费信息并内化为知识的手段,不过工欲善其事,必先利其器,我们需要有使用起来得心应手的软件。Tiago 在提出 CODE 方法来实践第二大脑的时候,并没有使用大语言模型这样的 AI 工具;但在这一年来的时间里,ChatGPT、Claude 还有 Google Bard 展现出来的能力,让大家直接跃进到了智能时代,我们处理语言与数据的效率得到了指数级的提升,这会深远的影响到软件工具的使用、设计以及我们对知识管理与传播的认知方式。
专业用户的武器库
放心,不用被武器库吓到了!如果你不是一名重度信息整理依赖症患者,或者你已经参悟到了整理信息的禅意,Apple Notes 就可以满足你所有的需求,快速记录与检索、无排版压力、支持链接、图片还有 PDF 以及手写,还能通过 iCloud 云端保存。
如果你只想用一款软件来构建自己的外脑,那就是 Apple Notes 📒
但对于一名日常阅读量巨大还经常要做内容输出的专业用户(Pro User),或者是重度知识工作者,还是希望捕获的效率更高、条理更清晰,有足够的空间让自己思考和创作。我按照自己的工作流,整理更新了一份「INDIGO 的外脑工具集」分享给大家。
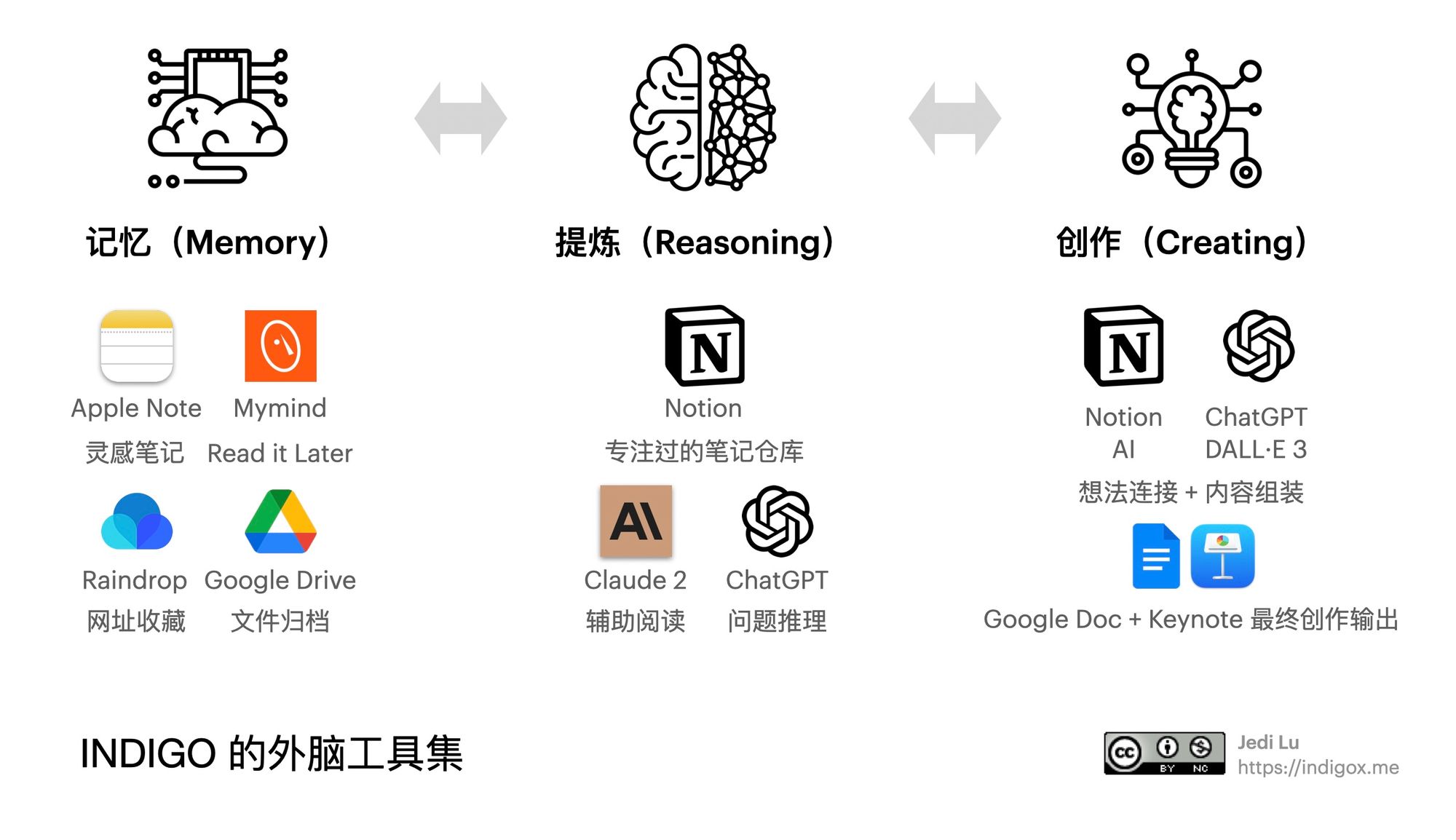
记忆(Memory)
- Apple Note:个人灵感笔记本,短创作和快速捕获的任何东西;
- Mymind:全部的阅读收藏(Read It Later),文章、视频、播客、图片等等,Mymind 有很好的检索、自动化标签还有个超级赞的遗忘功能,特别适合做定期清理,避免收藏信息膨胀;
- Raindrop:网站收藏夹,用于独立站点、工具等非内容类的资料;
- Google Drive:全部个人创作的文章,演讲稿,还有收藏的大块头 PDF 等等,Google 对这些资料的检索速度和准确度是最高的;
提炼(Reasoning)
在灵感捕获法里面已经分享了,Notion 是我自己最完善的笔记资料库,所有「专注」过的内容,都会通过笔记的方式写入 Notion,这里是自己的想法仓库。有了新的心智界面,大语言模型驱动的智能对话服务,现在很多长文可以让它们帮忙加速阅读和理解,而且还能做延展解释,这些生成的内容,也会保存到 Notion,日后使用。
Claude 2 是我现在最常用的 PDF 与长文阅读器,可以多文章对比阅读,另外 ChatGPT 配合 ShowMe 和 WebPilot 插件也会非常有效,特别是集成了 GPT-4V 多模态后,一些图表的解释很方便,结果配合原图一起保存。LLMs / LMMs 帮外脑实现了理解能力,这是工具的飞跃!
创作(Creating)
Notion 是最主要的外脑想法组装工厂,因为所有的「专注」过程产生的笔记都在这里,Notion AI 会对创作有些帮助,用来延展和修改内容。ChatGPT 在输出内容品质上的感觉是最好的,配合 Notion 一起使用,最后用 Google Doc 来完成输出的交付物。
大语言模型驱动的这些智能对话工具,已经作为智能副驾(Copilot)进入我现在的工作流了。很快,它们就会成为用户使用工具的入口,微软在今年三月 GPT-4 刚推出的时候,就宣布了自己的 Office 套件会集成 GPT-4 作为它的 Copilot 能力,而且 OneNote 将是首个可以 Copilot 的套件应用,计划在今年11月正式上线;智能争夺战的另外一边 Google 也宣布把 Bard 集成到了自己的全线产品,除了 Search 之外,Google Map 整合 Bard 能力,还有 Google Workspace,这里面包含了办公套件、Drive 还有 Gmail,几乎我们在 Google 留下的所有数据,都要对 Google 的大语言模型开放了。
Google 最早的愿景就是接管一切数据,现在它正在用 Bard 还有未来的大模型组织我们留在它那里的数据,如果我们只在 Google 的生态里选择工具,那 Google 已经在给我们提供外脑,Bard 正在成为 Google 和它用户之间的心智界面。
这里还有一家公司 OpenAI,虽然微软通过投资强行植入了 GPT-4 到自己的生态,但 Sam Altman 领导的 OpenAI 一定另有野心。ChatGPT 不到四个月就积累了一亿用户,已经成为了有史以来用户增长最快的软件,实现一款不依赖于手机还有电脑的全新智能硬件,或许很有想象空间,它将是每个人的智能伴侣。
ExoBrain 的集成软件
人类的需求是多样性的,永远不会有一种服务能满足所有人的不同,构建外脑的方案也是如此。科技巨头和 AI 先锋都希望占领最通用的市场,满足绝大多数人的需求,但一款流畅的能够服务 Pro User 的外脑工具,也显得十分必要。让专业人士的效率更高,也是一种在巨头垄断市场下的生成手段。
我们综合这篇文章提到的所有的概念、方法论还有工作流,这样一款工具的核心特点是什么?能帮助大家解决那些现在效率低下,需要很多工具组合才能解决的问题?
- 作为外脑的主要记忆空间,能够帮助捕获所有的数字内容,网页、视频、播客、PDF 以及各种复杂的数据格式,而且能够随时随地访问;
- 可以挂接和导入外部记忆,例如 Google Drive、Notion 以及 Read It Later 工具;
- 能帮助快速理解捕获的内容,我们直接在内部问答提取需要的知识,无需使用外部的智能对话服务,这样能极大提高效率;
- 可以灵活在里面创作笔记,也能够根据以前的笔记和捕获的信息,来生成创作建议,这是非常重要的想法连接器;
- 可以和自己的外脑知识库对话,代替简单的搜索,因为语言模型强化了搜索,我们能获得更多生成的准确信息,还能自动做外部检索来完善答案;
这款集成软件的目标是让信息无需组织,能够自己思考,帮助我们提升生物大脑的记忆和智能。今年成立的 Hallid.ai Lab 就正在开发一款这样的工具 Maimo.ai,希望我们小小的团队能够逐步实现自己写下的这些需求,第一个体验版会在今年十一月开放,关注 @hallidaiHQ 获取最新信息,欢迎届时体验。
配图10:Maimo ExoBrain Preview
Dan Shipper 在《The End of Organizing》这篇中提到过他对智能笔记的构想:
- 当在创作中提出一个观点时,它可能会建议一个引用来说明它;
- 当写一个决定时,它可能暗示支持(或反确认)过去的证据;
- 当撰写电子邮件时,它可以提取以前的会议记录来帮助表达自己的观点;
这样的体验可以让我们的笔记存档变成一个亲密的思想伙伴。将来,笔记不会由我们来组织,而是为我们组织,思考的终极工具是让工具会自己思考!在智能时代如何设计软件,是个非常有趣的话题,后续我会专门写文章来讨论。
后记:知识的重塑
你去问一个九十年代后期出生的年轻人,如果没有 搜索引擎 应该如何找资料,估计他会一脸茫然,翻阅图书馆这种行为他们应该都没见过;你再去问一个二十一世纪出生的零零后,如果没有 社交网络 应该如何获取资讯和分享生活,估计也会看到一脸疑惑的表情,报纸这种媒体理应只存在于社交网络里,生活也应该存在于朋友圈、TikTok 这样的社交网络中。。
人类进入了信息时代之后,搜索引擎让数字信息通过网页权重(PageRank)相连,我们创造的知识依赖搜索引擎的奖励机制传播;随后在移动互联网上发展壮大的社交网络,让数字信息通过社交权重(SocialRank)相连,我们创造的知识依赖社交推荐的奖励机制传播;现在,正在发生的生成式 AI 革命,正在吞噬搜索与社交网络时代的全部数字信息,训练成新的神经网络权重(ModuleRank),我们创造的知识依赖大模型来传播,例如向 ChatGPT 或 Google Bard 提问,人类很快就要面对一个新的现实,这个时代知识不一定由我们来创造了。在未来的几十年里,我们可能会看到 知识传播 境况的转变,但这种知识将不需要人类,而是由机器,通过 AI 来拥有和管理。
从一个比较哲学的角度来思考,如果知识被 AI 重塑,那么人的意义在哪里?在很多科幻片中,都有一种人造的超级智能,最终控制了人类,代替我们思考和决策。但我个人认为这种场景是不会出现的,大自然偏爱多样性,知名科学家 Wolfram 在他今年的这篇《Will AIs Take All Our Jobs and End Human History—or Not? Well, It’s Complicated…》中再次用他的 计算不可约 理论,证明了人类将与人工智能的共生。
超级智能会帮助我们强化自身,就像本文开头提到的:它是一个可以帮助我们充分发挥作为人类的潜力的伙伴。超级智能将是我们的外脑(ExoBrain),我们每个人独特的个性、经验和思考风格,将会与这些智能个体融合,成为我们的化身(Avatar),而且这个化身不一定要像元宇宙(Metaverse)中那种具象的存在,它就是我们的思维与 AI 模型融合而成的经验体,我们分享和消费这些独立的经验体,它们就是知识传播的纽带,它们和人类一起汇聚成了这个智能时代的新知识网络。
以上是作为一名 AI 乐观派、多样化与去中心主义信仰者的对知识传播未来的一点点畅想!
WORLD PEACE ☮️
参考
Building a Second Brain: The Definitive Introductory Guide - TIAGO FORTE
Building a Second Brain - Kunal's Blog
GPT-4: A Copilot for the Mind - DAN SHIPPER
The End of Organizing - DAN SHIPPER
Introducing Chat Notebooks: Integrating LLMs into the Notebook Paradigm - Stephen Wolfram
费曼学习法实践 / INDIGO 的信息获取与知识输出方法论 - Indigo's Digital Mirror